Machine Learning with Scikit Learn: linear regression
machine learning
Author
João Ramalho
Published
December 17, 2022
Introduction
This posts initiates a new series on Machine Learning with Python. Previous posts have focused on Machine Learning with R using the tidymodels framework. This new series follows the same kind of modelling workflow from data loading, feature engineering, modelling, predicting new values and evaluating model performance.
The main objectives of these posts is to serve as a cookbook for Machine Learning and be a complement of my book ‘industRial data science’ released in 2021 that doesn’t cover predictive.
Setup
My favorite configuration for Data Science has stabilized in RStudio with Quarto and the Reticulate package. In previous posts I have shown comparisons of different commercial software, programming languages and programming tools and IDEs. This RStudio-Quarto-Reticulate covers all use cases I can imagine both for professionals and non-professionals with the smallest configuration effort possible (still there is some!).
library(reticulate)library(here)
here() starts at /home/joao/JR-IA
py_discover_config()
python: /home/joao/JR-IA/renv/python/condaenvs/renv-python/bin/python
libpython: /home/joao/JR-IA/renv/python/condaenvs/renv-python/lib/libpython3.7m.so
pythonhome: /home/joao/JR-IA/renv/python/condaenvs/renv-python:/home/joao/JR-IA/renv/python/condaenvs/renv-python
version: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0]
numpy: /home/joao/JR-IA/renv/python/condaenvs/renv-python/lib/python3.7/site-packages/numpy
numpy_version: 1.21.6
NOTE: Python version was forced by RETICULATE_PYTHON
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import cross_val_score, KFold
Data load
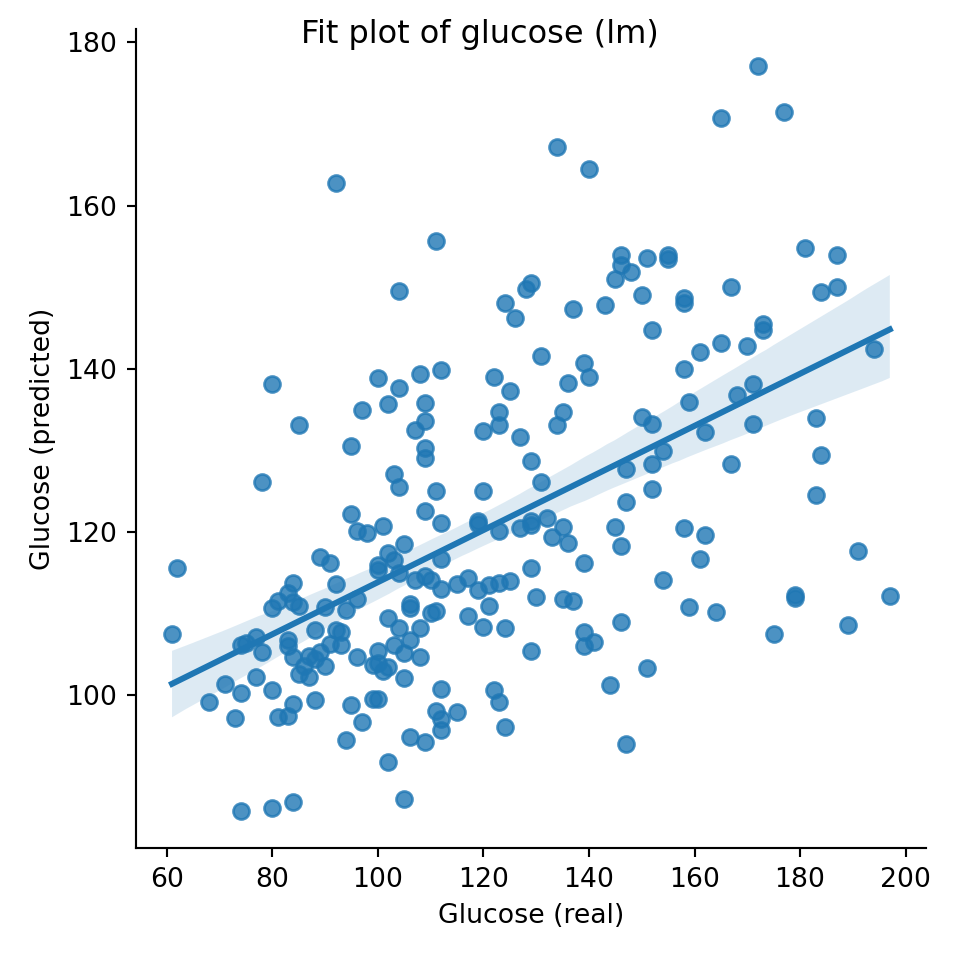
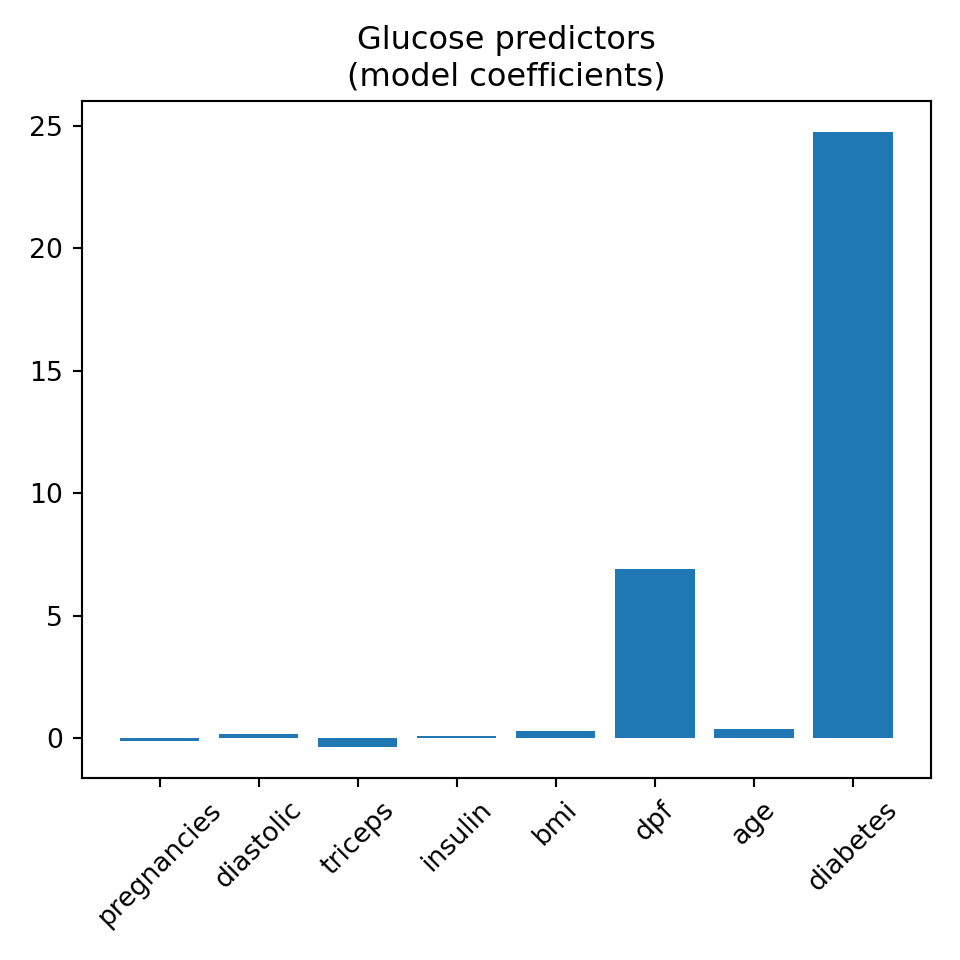
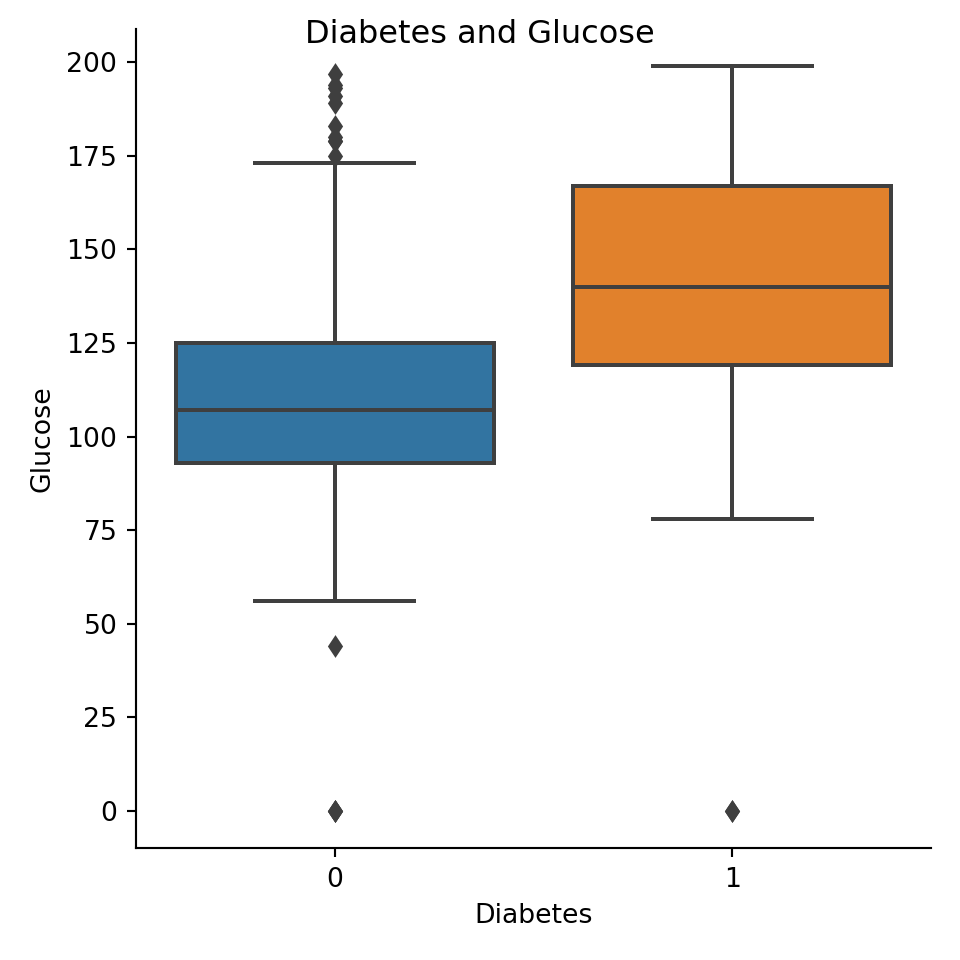
This example is based on the Data Camp course on Supervised Learning with Scikit learn. The dataset is quite interesting with several variables and close to 1000 datapoints. Although it is small from a machine learning point of view it is big enough for demonstration purposes.
As usual in Scikit learn models we have first to convert the dataframe to pandas arrays and separate inputs from outputs. This is heavier that in R where dataframes are kept together but there is certainly a speed trade off on the long term.
X = diabetes_df.drop("glucose", axis=1).valuesy = diabetes_df["glucose"].values
Multiple linear regression
We observe that in general the syntax is simpler than in R tidymodels and the workflow can be complete in just a few lines.
Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)